提供者:李华勇
地址:http://ai.stanford.edu/~amaas/data/sentiment/
背景介绍
在自然语言处理中,情感分析一般是指判断一段文本所表达的情绪状态。其中,一段文本可以是一个句子,一个段落或一个文档。情绪状态可以是两类,如(正面,负面),(高兴,悲伤);也可以是三类,如(积极,消极,中性)等等。情感分析的应用场景十分广泛,如把用户在购物网站(亚马逊、天猫、淘宝等)、旅游网站、电影评论网站上发表的评论分成正面评论和负面评论;或为了分析用户对于某一产品的整体使用感受,抓取产品的用户评论并进行情感分析等等。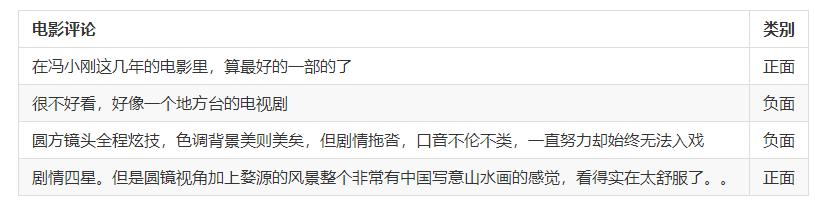
数据集介绍
这是一个二进制情绪分类数据集,其中包含比以前的基准数据集更多的数据。我们提供了一套25,000个的电影评论进行培训,25,000个进行测试。还有其他未标记的数据也可以使用。提供原始文本和已处理的文字格式包。
IMDB数据集的训练集和测试集分别包含25000个已标注过的电影评论。其中,负面评论的得分小于等于4,正面评论的得分大于等于7,满分10分。1
2
3
4
5
6
7aclImdb
|- test
|-- neg
|-- pos
|- train
|-- neg
|-- pos
下载地址
http://ai.stanford.edu/~amaas/data/sentiment/
相关论文
- Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).